
前言
程序员对哈希算法应该都不陌生,比如业界著名的MD5、SHA、CRC等等;在日常开发中我们经常用一个Map来装载一些具有(key,value)结构的数据,利用哈希算法O(1)的时间复杂度提高程序处理效率,除此之外,你还知道哈希算法的其他应用场景吗?
1. 什么是哈希算法?
了解哈希算法的应用场景前,我们先看下散列(哈希)思想,散列就是把任意长度的输入通过散列算法变换成固定长度的输出,输入称为Key(键),输出为Hash值,即散列值hash(key),散列算法即hash()函数(散列与哈希是对hash的不同翻译);实际上存储这些散列值的是一个数组,称为散列表,散列表用的是数组支持按照下标随机访问数据的特性,把数据值与数组下标按散列函数做的一一映射,从而实现O(1)的时间复杂度查询;
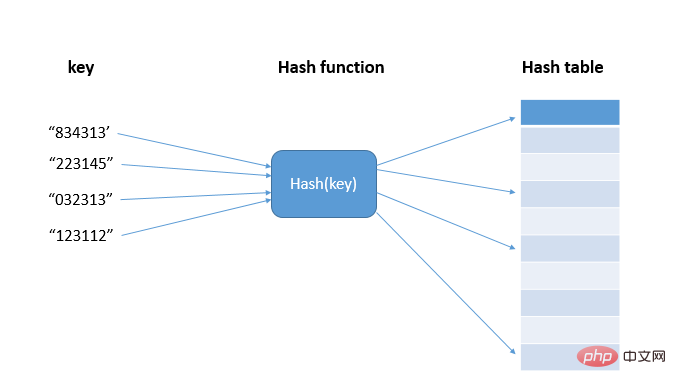
1.1 散列冲突
目前的哈希算法MD5、SHA、CRC等都无法做到一个不同的key对应的散列值都不一样的散列函数,即无法避免出现不同的key映射到同一个值的情况,即出现了散列冲突,而且,因为数组的存储空间有限,也会加大散列冲突的概率。如何解决散列冲突?我们常用的散列冲突解决方法有两类:开放寻址法(open addressing) 和 链表法(chaining)。
1.1.1 开放寻址法
通过线性探测的方法找到散列表中空闲位置,写入hash值:
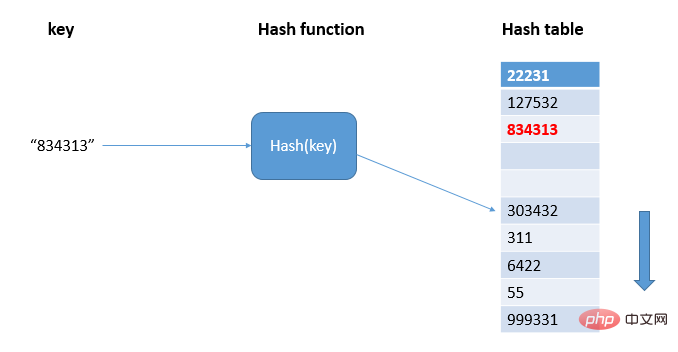
如图,834313在hash表中散列到303432的位置上,出现了冲突,则顺序遍历hash表直到找到空闲位置写入834313;当散列表中空闲位置不多的时候,散列冲突的概率就会大大增加,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位,此时,我们用装载因子来表示空闲位置的多少,计算公式是:散列表的装载因子=填入表中的元素个数/散列表的长度。装载因子越大,说明空闲位置越少,冲突越多,散列表的性能就会下降。
当数据量比较小,装载因子小的时候,适合采用开放寻址法,这也是java中的ThreadLocalMap使用开放寻址法解决散列冲突的原因。
1.1.2 链表法
链表法是一种更常用的散列冲突解决办法,也更简单。如图:
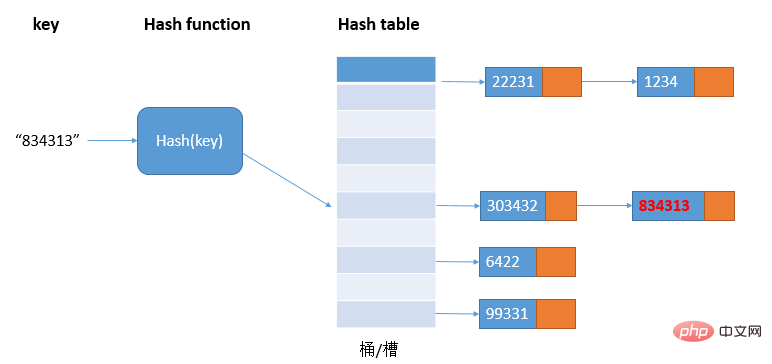
在散列表中,每个桶/槽会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中;当散列冲突比较多时,链表的长度也会变长,查询hash值需要遍历链表,这时查询效率就会从O(1)退化成O(n)。
这种解决散列冲突的处理方法比较适合大对象、大数据量的散列表,而且,支持
