作为JavaScript栏目开发人员,深入了解 JavaScript 引擎的工作原理有助于你了解自己代码的性能特征。这篇文章对所有 JavaScript 引擎中常见的一些关键基础知识进行了介绍,不仅仅局限于 V8 引擎。
JavaScript 引擎的工作流程 (pipeline)
这一切都要从你写的 JavaScript 代码开始。JavaScript 引擎解析源代码并将其转换为抽象语法树(AST)。基于 AST,解释器便可以开始工作并生成字节码。就在此时,引擎开始真正地运行 JavaScript 代码。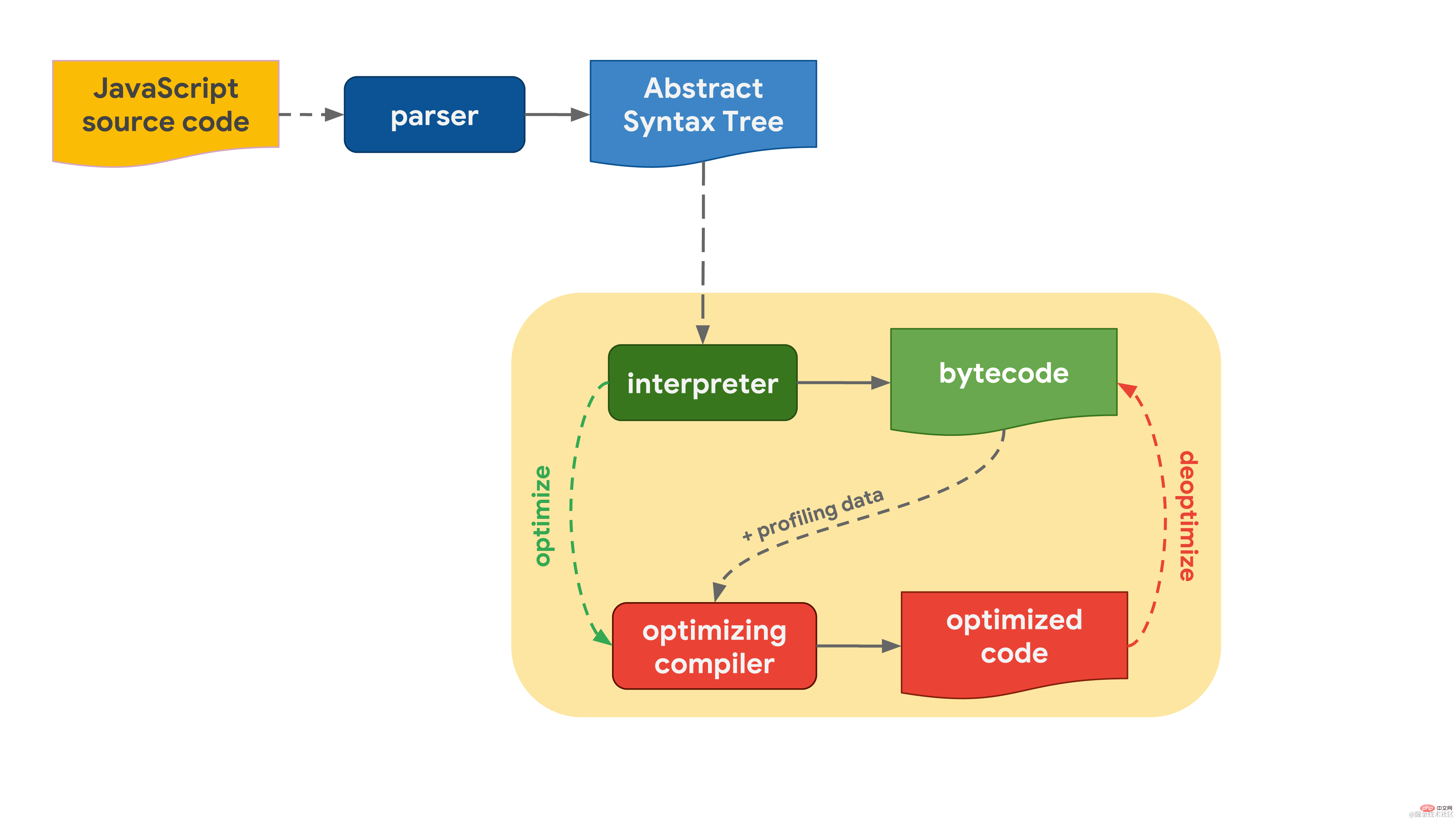 为了让它运行得更快,字节码能与分析数据一起发送到优化编译器。优化编译器基于现有的分析数据做出某些特定的假设,然后生成高度优化的机器码。
为了让它运行得更快,字节码能与分析数据一起发送到优化编译器。优化编译器基于现有的分析数据做出某些特定的假设,然后生成高度优化的机器码。
如果某个时刻某一个假设被证明是不正确的,那么优化编译器将取消优化并返回到解释器阶段。
JavaScript 引擎中的解释器/编译器工作流程
现在,让我们来看实际执行 JavaScript 代码的这部分流程,即代码被解释和优化的部分,并讨论其在主要的 JavaScript 引擎之间存在的一些差异。
一般来说,JavaSciript 引擎都有一个包含解释器和优化编译器的处理流程。其中,解释器可以快速生成未优化的字节码,而优化编译器会耗费更长的时间,但最终可生成高度优化的机器码。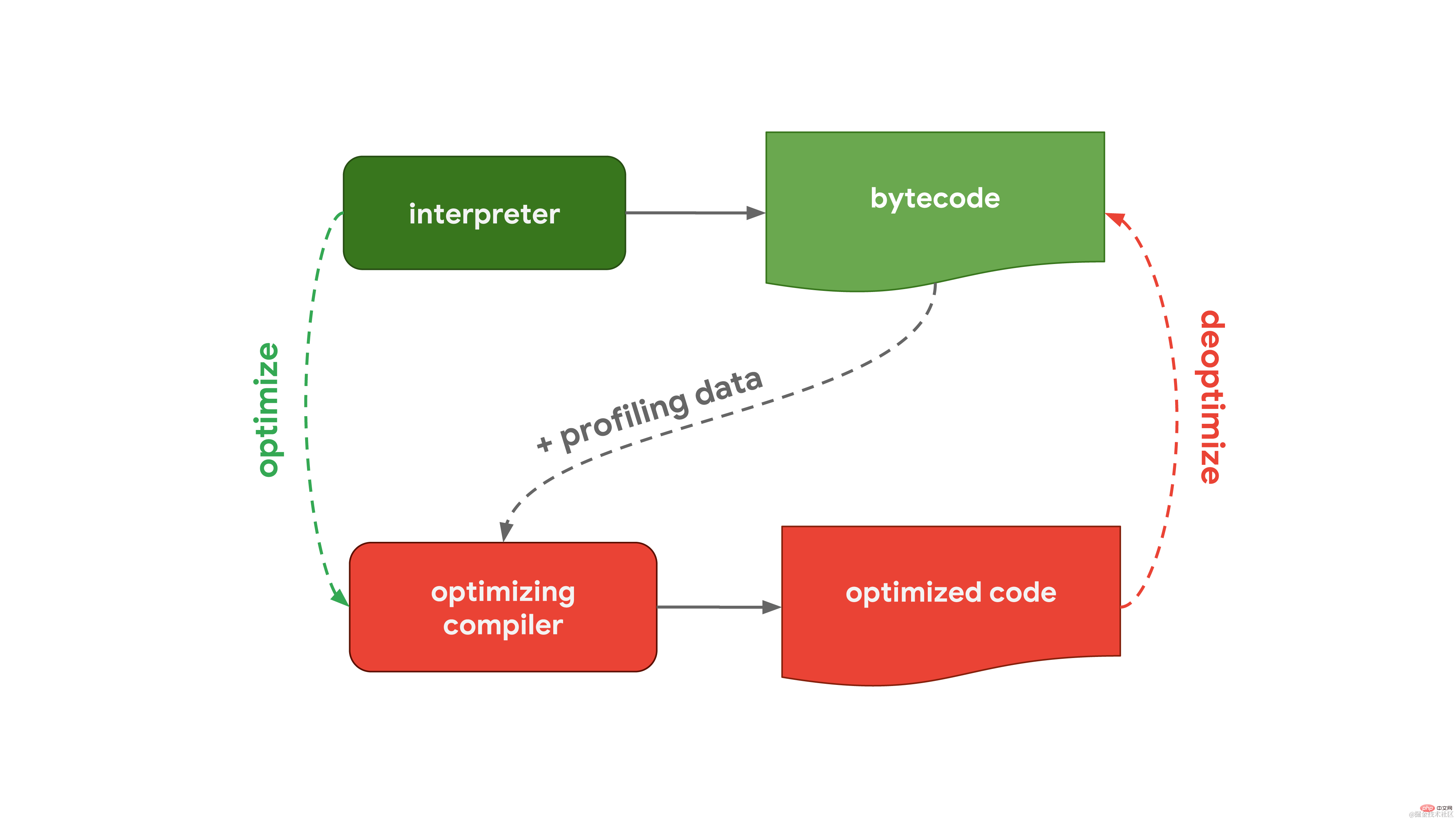 这个通用流程和 Chrome 和 Node.js 中使用的 Javascript 引擎, V8 的工作流程几乎一致:
这个通用流程和 Chrome 和 Node.js 中使用的 Javascript 引擎, V8 的工作流程几乎一致: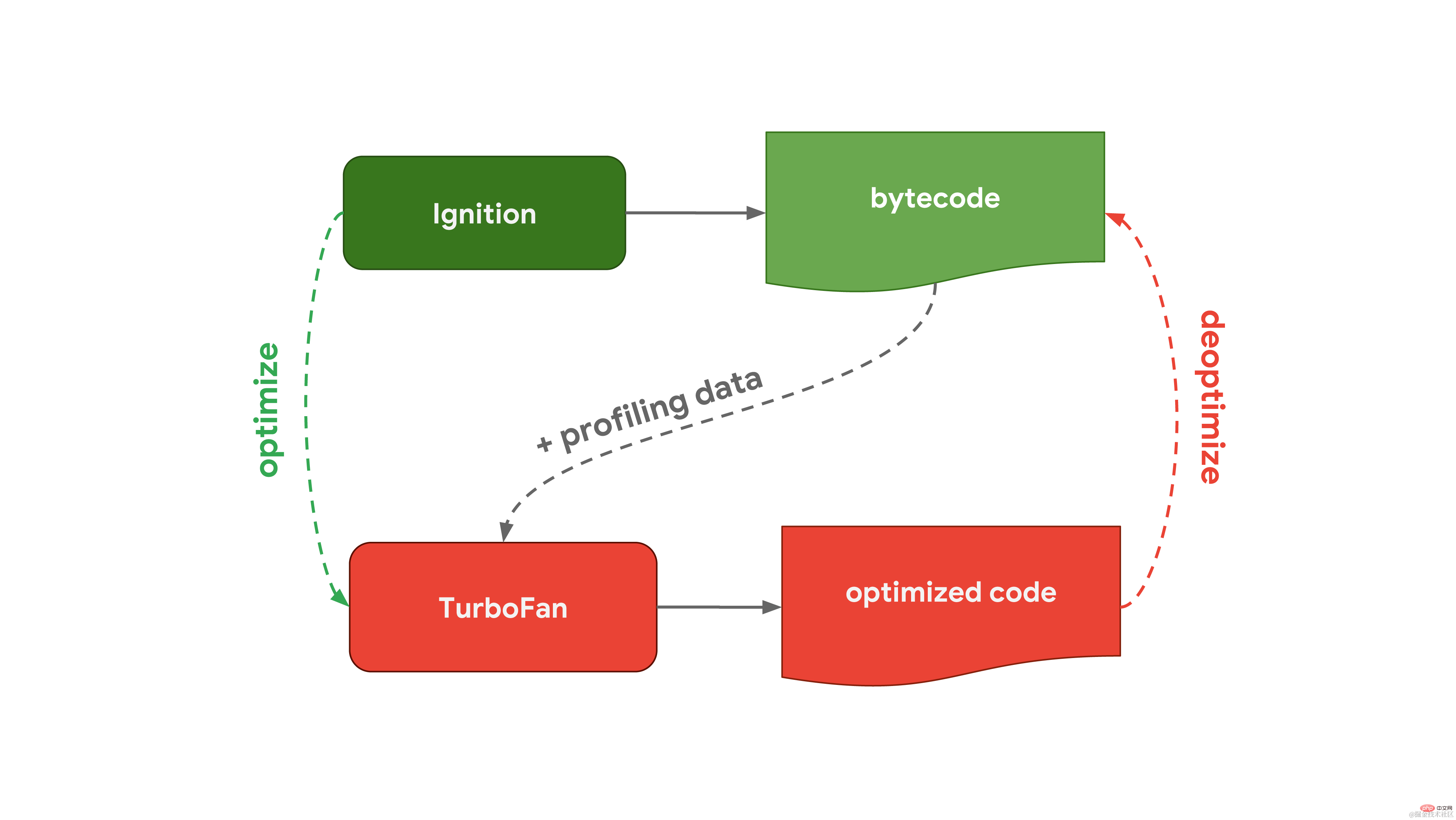 V8 中的解释器称为 Ignition,负责生成和执行字节码。当它运行字节码时,它收集分析数据,这些数据可用于后面加快代码的执行速度。当一个函数变为 hot 时,例如当它经常运行时,生成的字节码和分析数据将传递给我们的优化编译器 Turbofan,以根据分析数据生成高度优化的机器代码。
V8 中的解释器称为 Ignition,负责生成和执行字节码。当它运行字节码时,它收集分析数据,这些数据可用于后面加快代码的执行速度。当一个函数变为 hot 时,例如当它经常运行时,生成的字节码和分析数据将传递给我们的优化编译器 Turbofan,以根据分析数据生成高度优化的机器代码。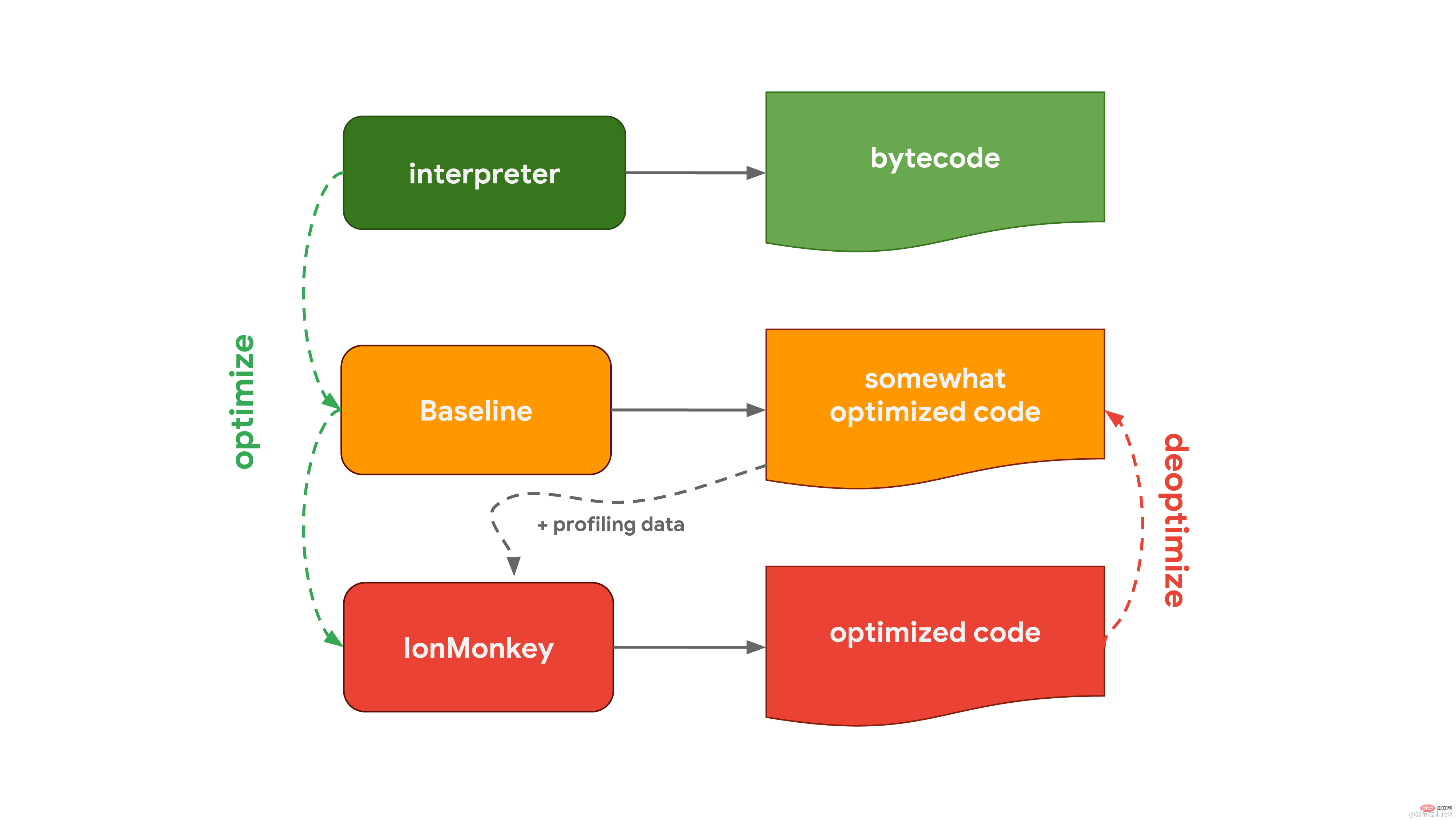 Mozilla 在 Firefox 和 Spidernode 中使用的 JavaScript 引擎 SpiderMonkey ,则不太一样。它们有两个优化编译器,而不是一个。解释器先通过 Baseline 编译器,生成一些优化的代码。然后,结合运行代码时收集的分析数据,IonMonkey 编译器可以生成更高程度优化的代码。如果尝试优化失败,IonMonkey 将返回到 Baseline 阶段的代码。
Mozilla 在 Firefox 和 Spidernode 中使用的 JavaScript 引擎 SpiderMonkey ,则不太一样。它们有两个优化编译器,而不是一个。解释器先通过 Baseline 编译器,生成一些优化的代码。然后,结合运行代码时收集的分析数据,IonMonkey 编译器可以生成更高程度优化的代码。如果尝试优化失败,IonMonkey 将返回到 Baseline 阶段的代码。
Chakra,在 Edge 中使用的 Microsoft 的 JavaScript 引擎,非常相似的,也有2个优化编译器。解释器优化代码到 SimpleJIT(JIT 代表 Just-In-Time 编译器,即时编译器),SimpleJIT 会生成稍微优化的代码。而 FullJIT 结合分析数据,可以生成更为优化的代码。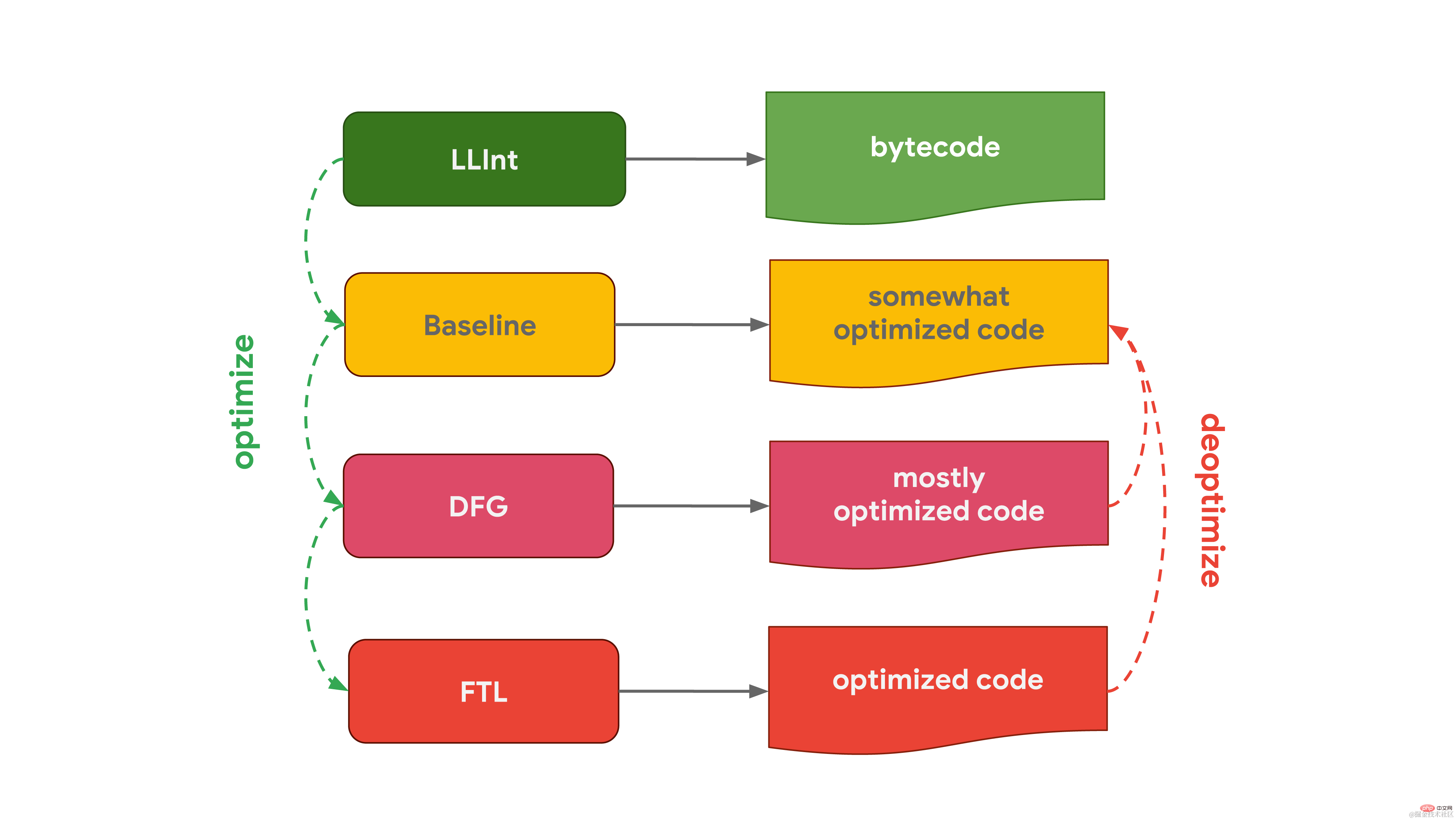 JavaScriptCore(缩写为 JSC),在 Safari 和 React Native 中使用的 Apple 的 JavaScript 引擎,它通过三种不同的优化编译器将其发挥到极致。低层解释器 LLInt 优化代码到 Baseline 编译器中,然后优化代码到 DFG(Data Flow Graph)编译器中,DFG(Data Flow Graph)编译器又可以将优化后的代码传到 FTL(Faster Than Light)编译器中。
JavaScriptCore(缩写为 JSC),在 Safari 和 React Native 中使用的 Apple 的 JavaScript 引擎,它通过三种不同的优化编译器将其发挥到极致。低层解释器 LLInt 优化代码到 Baseline 编译器中,然后优化代码到 DFG(Data Flow Graph)编译器中,DFG(Data Flow Graph)编译器又可以将优化后的代码传到 FTL(Faster Than Light)编译器中。
为什么有些引擎有
