
免费学习推荐:javascript学习教程
前端中的AST抽象语法树问题
- 四则运算
- 正则表达式
- 词法分析
- 语法分析
- 完整代码
四则运算
首先明确,此次的代码都是基于LL的语法分析来实现的,实现的是四则混合运算的功能,先看下定义:
TokenNumber:· 1 2 3 4 5 6 7 8 9 0 的组合
Operator:+ - * / 之一
WhiteSpace:<SP>
LineTerminator:<LF> <CR>
看下产生式:
正则表达式
我们首先实现正则表达式的匹配原则:
<script> var regexp = /([0-9.]+)|([ t]+)|([rn]+)|(*)|(/)|(+)|(-)/g var dictionary = ["Number", "Whitespace", "LineTerminator", "*", "/", "+", "-"]; function tokenize(source) { var result = null; while(true) { result = regexp.exec(source); if(!result) break; for(var i = 1; i <= dictionary.length; i ++) { if(result[i]) console.log(dictionary[i - 1]); } console.log(result); } } tokenize("1024 + 10 * 25");</script>
此时我们看一下页面的运行打印结果:
值得一提的是这里用到了exec方法,exec() 方法用于检索字符串中的正则表达式的匹配。
我们看一下它的语法:RegExpObject.exec(string)
如果 exec() 找到了匹配的文本,则返回一个结果数组。否则,返回 null。此数组的第 0 个元素是与正则表达式相匹配的文本,第 1 个元素是与 RegExpObject 的第 1 个子表达式相匹配的文本(如果有的话),第 2 个元素是与 RegExpObject 的第 2 个子表达式相匹配的文本(如果有的话),以此类推。除了数组元素和 length 属性之外,exec() 方法还返回两个属性。index 属性声明的是匹配文本的第一个字符的位置。input 属性则存放的是被检索的字符串 string。我们可以看得出,在调用非全局的 RegExp 对象的 exec() 方法时,返回的数组与调用方法 String.match() 返回的数组是相同的。
但是,当 RegExpObject 是一个全局正则表达式时,exec() 的行为就稍微复杂一些。它会在 RegExpObject 的 lastIndex 属性指定的字符处开始检索字符串 string。当 exec() 找到了与表达式相匹配的文本时,在匹配后,它将把 RegExpObject 的 lastIndex 属性设置为匹配文本的最后一个字符的下一个位置。这就是说,您可以通过反复调用 exec() 方法来遍历字符串中的所有匹配文本。当 exec() 再也找不到匹配的文本时,它将返回 null,并把 lastIndex 属性重置为 0。
词法分析
我们在这一部分对上面的代码做优化。
首先是刚才提到的:当 RegExpObject 是一个全局正则表达式时,exec() 的行为就稍微复杂一些。它会在 RegExpObject 的 lastIndex 属性指定的字符处开始检索字符串 string。当 exec() 找到了与表达式相匹配的文本时,在匹配后,它将把 RegExpObject 的 lastIndex 属性设置为匹配文本的最后一个字符的下一个位置。
那么我们就要考虑到没有匹配上字符的情况,做一个判断处理:
<script> var regexp = /([0-9.]+)|([ t]+)|([rn]+)|(*)|(/)|(+)|(-)/g var dictionary = ["Number", "Whitespace", "LineTerminator", "*", "/", "+", "-"]; function* tokenize(source) { var result = null; var lastIndex = 0; while(true) { lastIndex = regexp.lastIndex; result = regexp.exec(source); if(!result) break; if(regexp.lastIndex - lastIndex > result[0].length) break; let token = { type: null, value: null } for(var i = 1; i <= dictionary.length; i ++) { if(result[i]) token.type = dictionary[i - 1]; } token.value = result[0]; yield token } yield { type: 'EOF' } } for (let token of tokenize("1024 + 10 * 25")) { console.log(token) }</script>
如上,我们对regexp.lastIndex - lastIndex 和 result[0] 的长度进行比较,判断是否有字符串没有匹配上。
将整个函数改成generator函数的形式,我们看下运行的结果: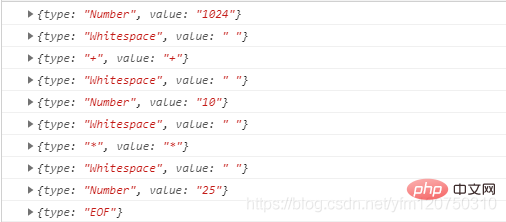
语法分析
首先编写分块的产生式,我们看一下总的代码结构:
<script> var regexp = /([0-9.]+)|([ t]+)|([rn]+)|(*)|(/)|(+)|(-)/g var dictionary = ["Number", "Whitespace", "LineTerminator", "*", "/", "+", "-"]; function* tokenize(source) { var result = null; var lastIndex = 0; while(true) { lastIndex = regexp.lastIndex; result = regexp.exec(source); if(!result) break; if(regexp.lastIndex - lastIndex > result[0].length) break; let token = { type: null, value: null } for(var i = 1; i <= dictionary.length; i ++) { if(result[i]) token.type = dictionary[i - 1]; } token.value = result[0]; yield token } yield { type: 'EOF' } } let source = []; for(let token of tokenize("10 * 25")) { if (token.type !== "Whitespace" && token.type !== "LineTerminator") source.push(token); } function Expression(tokens) { } function AdditiveExpression(source){ } function MultiplicativeExpresson(source) { console.log(source); } MultiplicativeExpresson("10 * 25")</script>
我们先从MultiplicativeExpresson来进行研究,它分为四种情况:
function MultiplicativeExpresson(source) { //如果是数字则进行封装 if(source[0].type === "Number") { let node = { type: "MultiplicativeExpresson", children:[source[0]] } source[0] = node; return MultiplicativeExpresson(source) } //如果是乘号或者除号,则将三项出栈,进行重组 if(source[0].type === "MultiplicativeExpresson" && source[1] && source[1].type === "*") { let node = { type: "MultiplicativeExpresson", operator: "*", children: [] } node.children.push(source.shift()); node.children.push(source.shift()); node.children.push(source.shift()); source.unshift(node); return MultiplicativeExpresson(source) } if(source[0].type === "MultiplicativeExpresson" && source[1] && source[1].type === "/") { let node = { type: "MultiplicativeExpresson", operator: "*", children: [] } node.children.push(source.shift()); node.children.push(source.shift()); node.children.push(source.shift()); source.unshift(node); return MultiplicativeExpresson(source) } //递归结束的条件 if(source[0].type === "MultiplicativeExpresson") return source[0]; return MultiplicativeExpresson(source); }
我们看一下当source为"10 * 25 / 2"时调用console.log(MultiplicativeExpresson(source))最后运行的结果:
接下来看AdditiveExpression 本质上和MultiplicativeExpresson没有什么不同,差异点已经标注在代码当中了:
function AdditiveExpression(source){ if(source[0].type === "MultiplicativeExpresson") { let node = { type: "AdditiveExpression", children:[source[0]] } source[0] = node; return AdditiveExpression(source) } //如果是乘号或者除号,则将三项出栈,进行重组 if(source[0].type === "AdditiveExpression" && source[1] && source[1].type === "+") { let node = { type: "AdditiveExpression", operator: "+", children: [] } node.children.push(source.shift()); node.children.push(source.shift()); //考虑到第三个数可能时Number 需要在这里再次调用一下 MultiplicativeExpresson 做处理 MultiplicativeExpresson(source); node.children.push(source.shift()); source.unshift(node); return AdditiveExpression(source) } if(source[0].type === "AdditiveExpression" && source[1] && source[1].type === "-") { let node = { type: "AdditiveExpression", operator: "-", children: [] } node.children.push(source.shift()); node.children.push(source.shift()); MultiplicativeExpresson(source); node.children.push(source.shift()); source.unshift(node); return AdditiveExpression(source) } //递归结束的条件 if(source[0].type === "AdditiveExpression") return source[0]; //第一次进循环 调用 MultiplicativeExpresson(source); return AdditiveExpression(source); }
我们看一下当source为"10 * 25 / 2"时调用console.log(AdditiveExpression(source))最后运行的结果: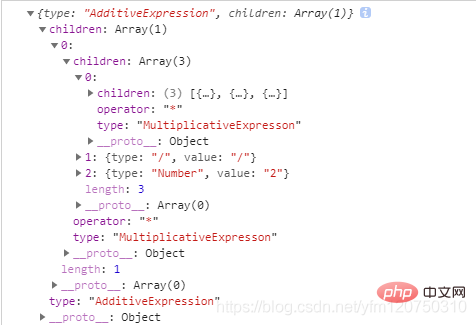
那么Expression的代码逻辑就很好表达了:
function Expression(tokens) { if(source[0].type === "AdditiveExpression" && source[1] && source[1].type === "EOF") { let node = { type: "Expression", children: [source.shift(), source.shift()] } source.unshift(node); return node; } AdditiveExpression(source); return Expression(source); }
看下运行后的结果:
