10 月 12 日消息 语言模型(Language Model)简单来说就是一串词序列的概率分布,主要作用是为一个长度为 m 的文本确定一个概率分布 P,表示这段文本存在的可能性。
大家之前可能或多或少听说过 GPT-3,OpenAI 最新的语言模型,堪称地表最强语言模型,也被认为是革命性的人工智能模型。除此之外还有 BERT、Switch Transformer 等重量级产品,而且业内其他企业也在努力推出自家的模型。
微软和英伟达今天宣布了由 DeepSpeed 和 Megatron 驱动的 Megatron-Turing 自然语言生成模型(MT-NLG),这是迄今为止训练的最大和最强大的解码语言模型。
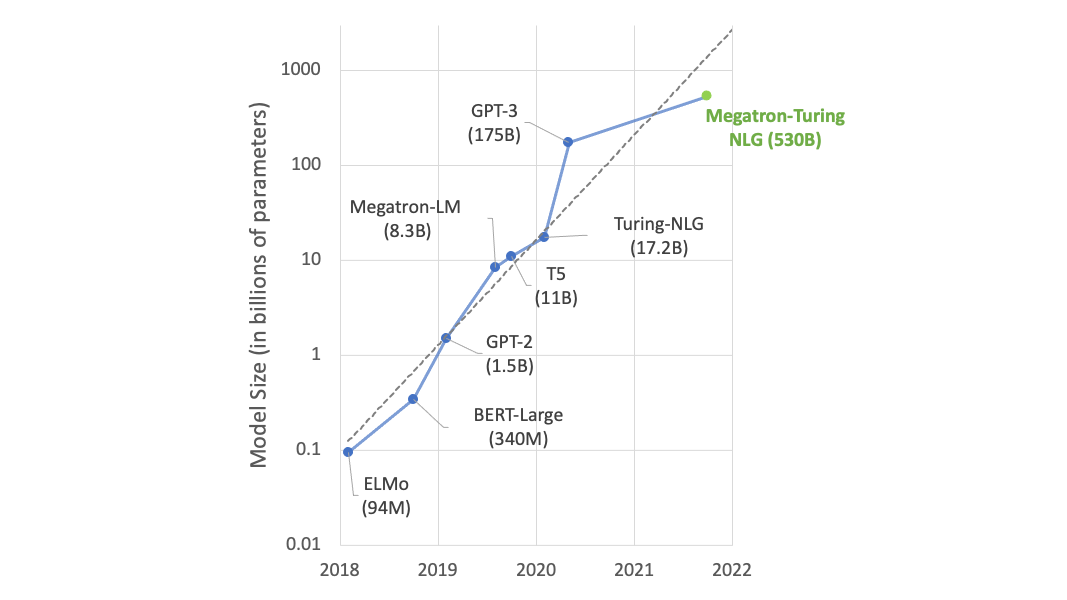
作为 Turing NLG 17B 和 Megatron-LM 的继任者,这个模型包括 5300 亿个参数,而且 MT-NLG 的参数数量是同类现有最大模型 GPT-3 的 3 倍,并在一系列广泛的自然语言任务中展示了无与伦比的准确性,例如:
完成预测
阅读理解
常识推理
自然语言推理
词义消歧
105 层、基于转换器的 MT-NLG 在零、单和少样本设置中改进了先前最先进的模型,并为两个模型规模的大规模语言模型设定了新标准和质量。
据悉,模型训练是在基于 NVIDIA DGX SuperPOD 的 Selene 超级计算机上以混合精度完成的,该超级计算机由 560 个 DGX A100 服务器提供支持,这些服务器以完整的胖树(FatTree)配置与 HDR InfiniBand 联网。每个 DGX A100 有 8 个 NVIDIA A100 80GB Tensor Core GPU,通过 NVLink 和 NVSwitch 相互完全连接。微软 Azure NDv4 云超级计算机使用了类似的参考架构。

特别提醒:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕。
