如何优化sql中的orderBy语句?下面本篇文章给大家介绍一下优化sql中orderBy语句的方法,具有很好的参考价值,希望对大家有所帮助。

程序员必备接口测试调试工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api设计、调试、文档、自动化测试工具
后端、前端、测试,同时在线协作,内容实时同步
在使用数据库进行数据查询时,难免会遇到基于某些字段对查询的结果集进行排序的需求。在sql中通常使用orderby语句来实现。将需要排序的字段放到 该关键词后,如果有多个字段的话,就用","分割。
select * from table t order by t.column1,t.column2;
登录后复制
上面的sql表示查询表table中数据,然后先按照column1排序,如果column1相同的话,在按照column2排序,排序的方式默认是降序。当然排序方式也是可以指定的。在被排序字段后添加 DESC,ASE,分别表示降序和升序。
使用该orderby可以很方便的实现日常的排序操作。使用的多了,不知道你有没有遇到过这种场景:有时候使用orderby后,sql执行效率非常慢,有时候却比较快,由于整天被curd缠身,也没有时间研究,反正就是觉得很神奇。趁这个周末比较闲,就来研究下,mysql中orderby是怎么实现的。
为了方便描述,我们先建立一个数据表 t1,如下:
CREATE TABLE `t1` ( `id` int(11) NOT NULL not null auto_increment, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) , KEY `a` (`a`) USING BTREE ) ENGINE=InnoDB;
登录后复制
并插入数据:
insert into t1 (a,b,c) values (1,1,3); insert into t1 (a,b,c) values (1,4,5); insert into t1 (a,b,c) values (1,3,3); insert into t1 (a,b,c) values (1,3,4); insert into t1 (a,b,c) values (1,2,5); insert into t1 (a,b,c) values (1,3,6);
登录后复制
为了使索引生效,插入10000行 7,7,7,无关数据,数据量少的情况下,会直接全表扫描
insert into t1 (a,b,c) values (7,7,7);
登录后复制
我们现在需要查找 a=1的所有记录,然后按照b字段进行排序。
查询sql为
select a,b,c from t1 where a = 1 order by b limit 2;
登录后复制
为了防止在查询过程中全表扫描,我们在字段a上添加了索引。
首先我们先通过语句
explain select a,b,c from t1 where a = 1 order by b lmit 2;
登录后复制
查看sql的执行计划,如下所示:

在extra中我们可以看到出现了Using filesort,这个表示 该sql执行过程中,执行了排序操作,排序操作在 sort_buffer中完成,sort_buffer是mysql分配给每个线程的一个内存缓冲区,该缓冲区专门用来完成排序,大小默认是1M,其大小由变量 sort_buffer_size 进行控制。
mysql在对orderby进行实现时,根据放入到sort_buffer中的字段内容不同,进行了两种不同实现方式:全字段排序和rowid排序。
全字段排序
首先我们先通过一张图整体看一下sql执行过程:
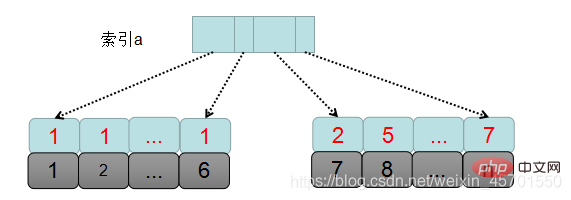
mysql先根据查询条件确定需要排序的数据集,也就是表中 a=1的数据集,即主键id从1到6的这些记录。
整个sql的执行的过程如下:
1.创建并初始化sort_buffer,并确定需要放到该缓冲区中的字段,也就是a,b,c这三个字段。
2.从索引树a中找到第一个满足a=1的主键id,也就是id=1。
3.回表到id索引,取出整行数据,然后从整行数据中,取出a,b,c的值,放入到sort_buffer中。
4.从索引a中按照顺序找到下一个a=1的主键id。
5.重复步骤3和步骤4,直到获取到最后一个a=1的记录,也就是主键id=5。
6.此时满足条件a=1的所有记录的 a,b,c字段,全部读放到了sort_buffer中,然后,对这些数据按照b的值进行进行排序,排序的方式是快速排序。就是那个面试经常面到的快速排序,时间复杂度为log2n的快速排序。
7.然后从排序后的结果集中取出前2行数据。
上面是就是msql中orderby的执行流程。因为放入到sort_buffer中的数据是需要输出的全部字段,所以这种排序被称为全排序。
看到这里不知道你是否会有疑问?如果需要排序的数据量很大的话,sort_buffer装不下怎么办?
的确,如果a=1的数据行特别多,且需要存放到sort_buffer中的字段比较多,可能不止a,b,c三个字段,有些业务可能需要输出
