
做爬虫不用说,就是用python就好,一个requests包走天下。但是呢,听说golang中内置的http包非常牛逼,咱就是说不得整点活,也刚好学习学习新东西,复习下http协议的请求和响应相关的知识点。话不多说,咱直接开整
本文章爬下必应壁纸先小试牛刀。狗头保命 狗头保命 狗头保命
爬虫流程概述
graph TD 请求数据 --> 解析数据 --> 数据入库
登录后复制
上图的流程图大家可以看到,其实爬虫并不麻烦,整个流程就只有三步而已。接下来具体聊聊每一步需要做什么
-
请求数据:在这里我们需要使用golang中的内置包http包向目标地址发起请求,这一步就完成了
-
解析数据:这里我们需要对请求到的数据进行解析,因为不是整个请求到的数据我们都需要,我们只需要某些具体的关键的数据而已。这一步也叫数据清洗
-
数据入库:不难理解,这就是将解析好的数据进行入库操作
实战分析
先到必应壁纸官网上观察,做爬虫的话是需要对数据特别敏感的。这是首页信息,整个页面是非常简洁的
接下来,需要调出浏览器的开发者工具(这个大家应该都非常熟悉吧,不熟悉的话很难跟下去的喔)。直接按下F12或者右键点击检查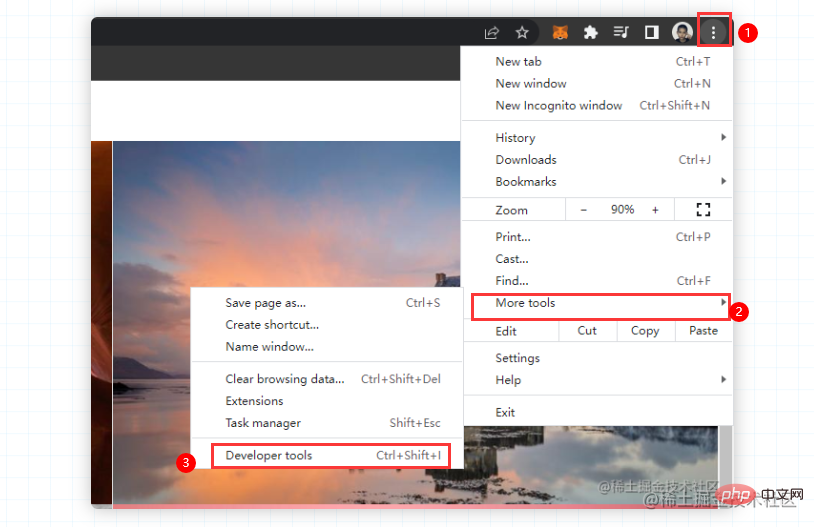
 但是呢?在必应壁纸上,右键不能调用控制台,只能手动调出了。大家不用担心,按照第一张图操作就好。如果有同学的chrome是中文的,也是一样的操作,选择
但是呢?在必应壁纸上,右键不能调用控制台,只能手动调出了。大家不用担心,按照第一张图操作就好。如果有同学的chrome是中文的,也是一样的操作,选择
