
前言
现在知乎允许上传视频,奈何不能下载视频,好气哦,无奈之下研究一下了,然后撸了代码,方便下载视频保存。
接下来以 猫为什么一点也不怕蛇? 回答为例,分享一下整个下载过程。
相关学习推荐:python视频教程
调试一下
打开 F12, 找到光标,如下图:
然后将光标移动到视频上。如下图:
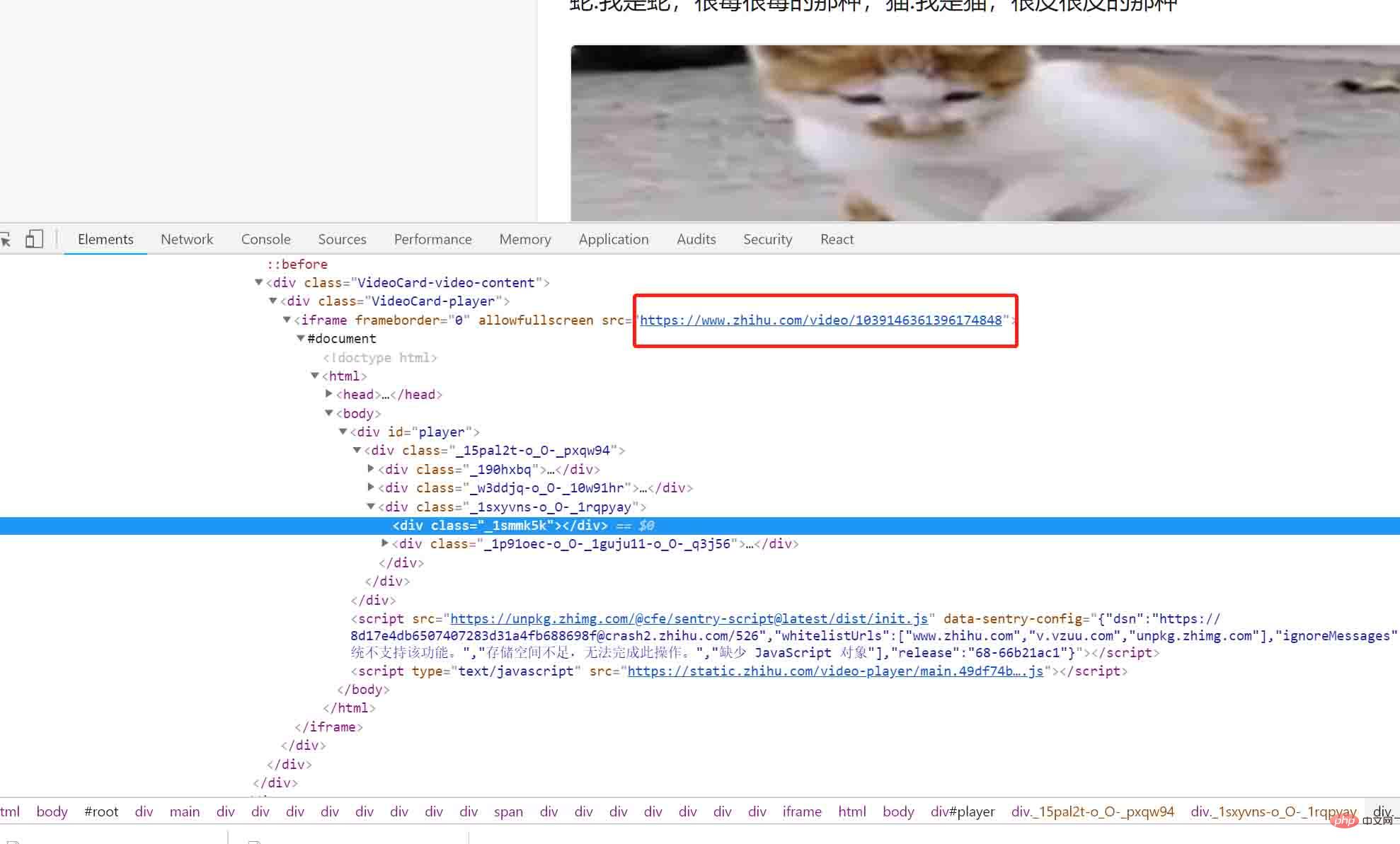
咦这是什么?视野中出现了一条神秘的链接: https://www.zhihu.com/video/xxxxx,让我们将这条链接复制到浏览器上,然后打开:
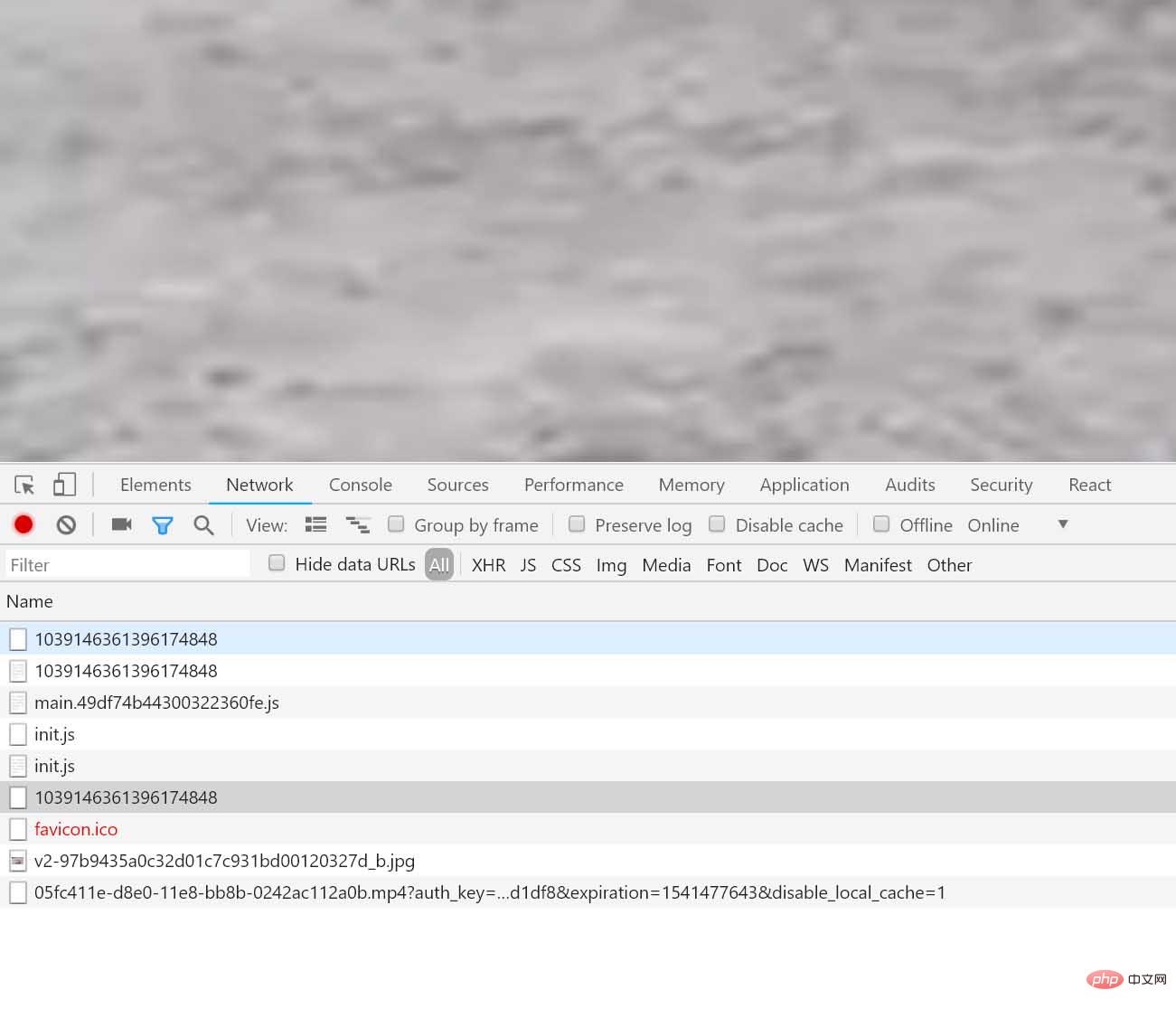
似乎这就是我们要找的视频,不要着急,让我们看一看,网页的请求,然后你会发现一个很有意思的请求(重点来了):
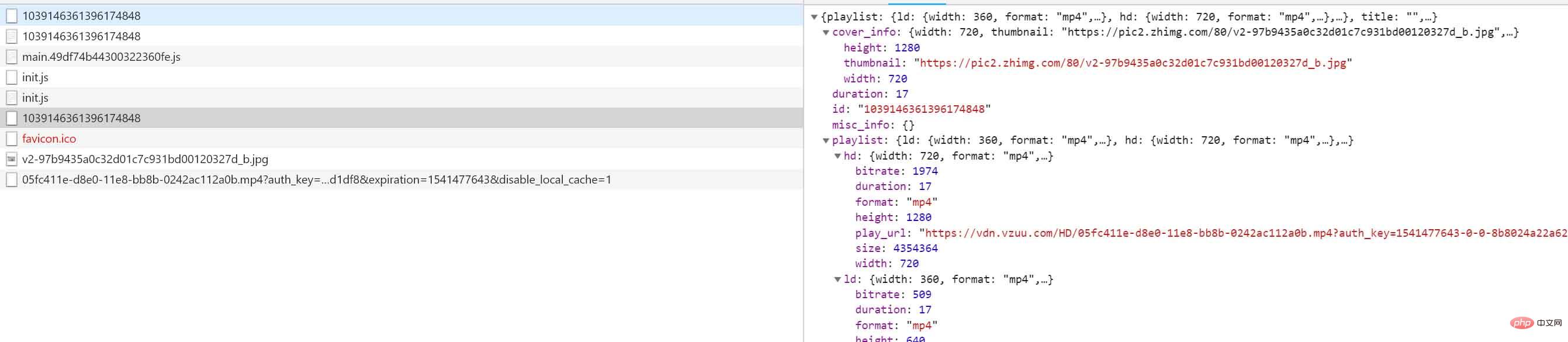
让我们自己看一下数据吧:
{ "playlist": { "ld": { "width": 360, "format": "mp4", "play_url": "https://vdn.vzuu.com/LD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-987c2c504d14ab1165ce2ed47759d927&expiration=1541477643&disable_local_cache=1", "duration": 17, "size": 1123111, "bitrate": 509, "height": 640 }, "hd": { "width": 720, "format": "mp4", "play_url": "https://vdn.vzuu.com/HD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-8b8024a22a62f097ca31b8b06b7233a1&expiration=1541477643&disable_local_cache=1", "duration": 17, "size": 4354364, "bitrate": 1974, "height": 1280 }, "sd": { "width": 480, "format": "mp4", "play_url": "https://vdn.vzuu.com/SD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-5948c2562d817218c9a9fc41abad1df8&expiration=1541477643&disable_local_cache=1", "duration": 17, "size": 1920976, "bitrate": 871, "height": 848 } }, "title": "", "duration": 17, "cover_info": { "width": 720, "thumbnail": "https://pic2.zhimg.com/80/v2-97b9435a0c32d01c7c931bd00120327d_b.jpg", "height": 1280 }, "type": "video", "id": "1039146361396174848", "misc_info": {} }
没错了,我们要下载的视频就在这里面,其中 ld 代表普清,sd 代表标清, hd 代表高清,把相应链接再次在浏览器打开,然后右键保存就可以下载视频了。
代码
知道整个流程是什么样子,接下来撸代码的过程就简单了,这里就不过再做过多解释了,直接上代码:
# -*- encoding: utf-8 -*- import re import requests import uuid import datetime class DownloadVideo: __slots__ = [ 'url', 'video_name', 'url_format', 'download_url', 'video_number', 'video_api', 'clarity_list', 'clarity' ] def __init__(self, url, clarity='ld', video_name=None): self.url = url self.video_name = video_name self.url_format = "https://www.zhihu.com/question/d+/answer/d+" self.clarity = clarity self.clarity_list = ['ld', 'sd', 'hd'] self.video_api = 'https://lens.zhihu.com/api/videos' def check_url_format(self): pattern = re.compile(self.url_format) matches = re.match(pattern, self.url) if matches is None: raise ValueError( "链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}" ) return True def get_video_number(self): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } response = requests.get(self.url, headers=headers) response.encoding = 'utf-8' html = response.text video_ids = re.findall(r'data-lens-id="(d+)"', html) if video_ids: video_id_list = list(set([video_id for video_id in video_ids])) self.video_number = video_id_list[0] return self raise ValueError("获取视频编号异常:{}".format(self.url)) except Exception as e: raise Exception(e) def get_video_url_by_number(self): url = "{}/{}".format(self.video_api, self.video_number) headers = {} headers['Referer'] = 'https://v.vzuu.com/video/{}'.format( self.video_number) headers['Origin'] = 'https://v.vzuu.com' headers[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' headers['Content-Type'] = 'application/json' try: response = requests.get(url, headers=headers) response_dict = response.json() if self.clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] else: for clarity in self.clarity_list: if clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] break return self except Exception as e: raise Exception(e) def get_video_by_video_url(self): response = requests.get(self.download_url) datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S") if self.video_name is not None: video_name = "{}-{}.mp4".format(self.video_name, datetime_str) else: video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str) path = "{}".format(video_name) with open(path, 'wb') as f: f.write(response.content) def download_video(self): if self.clarity not in self.clarity_list: raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)") if self.check_url_format(): return self.get_video_number().get_video_url_by_number().get_video_by_video_url() if __name__ == '__main__': a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069') print(a.download_video())
结语
代码还有优化空间,这里面我只是下载了回答中的第一个视频,理论上应该存在一个回答下可以有多个视频的。如果还有什么疑问或者建议,可以多多交流。
相关学习推荐:python视频教程
