12月1日,国际人工智能顶级会议AAAI 2022论文接受结果公布!本届会议共收到全球的9215篇投稿论文,接受率为15%。AAAI(Association for the Advance of Artificial Intelligence)是由国际人工智能促进协会主办的年会,是人工智能领域中历史最悠久、涵盖内容最广泛的国际顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。
本次腾讯优图实验室共有14篇论文被收录,涵盖语义分割、图像着色、人脸安全、弱监督目标定位、场景文本识别等前沿领域。
以下为部分入选论文:
01
视频异常检测双向预测网络中的全面正则化方法
Comprehensive Regularization in a Bi-directional Predictive Network for Video Anomaly Detection
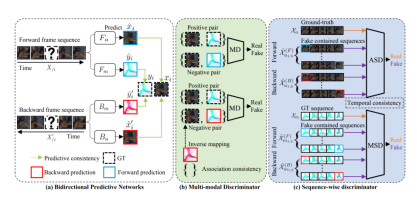
视频异常检测任务旨在通过学习正常视频的特征,自动识别视频中异常的目标或行为。此前的方法倾向于利用简单的重建或预测约束,这将导致从正常视频中学习特征不充分。基于此,我们提出一种包含三种一致性约束的双向架构,能够从像素级、跨模态和时间序列三个层面对预测任务做全面正则化。第一,我们提出预测的一致性,它考虑前后时序中运动的对称性质,进而保证在像素级层面的高真实性外观和运动预测。第二,我们提出关联的一致性,它考虑不同模态的相关性并使用其中一种模态来正则化另一种模态的预测。最后,我们提出时序一致性,它利用视频序列的关系保证预测网络生成时序上一致的帧。在推理阶段,异常帧的模式由于无法预测从而导致更高的预测错误置信度。实验结果显示本文方法效果超过了多种先进的异常检测器,并在UCSD Ped2、22 CUHK Avenue和ShanghaiTech等数据集上取得了SOTA效果。
02
基于域不变表征学习的可泛化语义分割方法
DIRL: Domain-invariant Representation Learning for Generalizable Semantic Segmentation
在真实世界应用中,模型对未知场景的泛化能力是至关重要的,比如自动驾驶就需要鲁棒的视觉系统。目前通过学习域不变的特征来增强模型泛化能力已被广泛研究,然而大部分现有的研究工作都在关注学习不同域之间公共的特征空间,而忽视了特征本身的性质(比如对域相关风格的敏感度)。因此,我们提出了一种新的域泛化方法:利用特征敏感度特性作为特征先验来引导模型训练以便提升模型泛化能力。具体而言,1)提出特征校准模块(PGAM)来强化不敏感特征并抑制敏感特征 2)引入新的特征白化方法(GFW)进一步弱化对域风格敏感相关的特征。通过对域风格敏感特征的抑制,我们可以学习到域不变特征表达,从而大大加强模型泛化能力。我们的方法简单且有效,在几乎不增加计算成本情况下可以增强各种主干网路的特征鲁棒性。大量的实验结果证明我们的方法在域泛化语义分割任务上明显优于其他方法。

03
SCSNet: 一种同时学习图像着色和超分高效方法
SCSNet: An Efficient Paradigm for Learning Simultaneously Image Colorization and Super-Resolution
在复原低分辨率灰度图像的实际应用中,通常需要进行图像着色、超分辨率和降采样三个单独的过程。然而,这种pipeline是冗余且不高效的。因此,我们提出了一种同时执行图像着色和超分辨率的有效范式,并提出了一种端到端SCSNet来实施。该方法由两部分组成:其一,用于学习颜色信息的着色分支,该分支使用所提出的即插即用金字塔阀交叉注意(PVCAttn)模块,在源图像和参考图像之间聚合特征映射。其二,超分辨率分支,用于集成颜色和纹理信息以预测目标图像,该分支使用连续像素映射(CPM)在连续空间中预测高分辨率图像。此外,我们的SCSNet支持“自动上色”和“参考上色”两种模式,更适合实际应用。大量的实验证明了我们的方法的优越性, 与自动模式和参考模式下,在多个数据集上FID平均降低1.8 和5.1。 此外,我们的方法相比于SOTA基线具有更少的参数量(x2↓)和更快的运行速度(x3↑)。

04
LCTR:唤醒弱监督目标定位中Transformer的局部拓展性
LCTR: On Awakening the Local Continuity of Transformer for Weakly Supervised Object Localization
弱监督目标定位(WSOL)旨在实现仅给定图像级标签的前提下学习一个目标定位器。基于卷积神经网络的技术往往会过分突出目标最具判别力的区域从而导致忽略目标的整体轮廓。最近,基于自注意力机制和多层感知器结构的transformer因其可以捕获长距离特征依赖而在WSOL中崭露头角。美中不足的是,transformer类的方法缺少基于CNN的方法中固有的局部感知倾向,从而容易在WSOL中丢失局部特征细节。在本文中,我们提出了一个基于transformer的新颖框架,叫作LCTR(局部拓展性Transformer),来在transformer中长距离全局特征的的基础上增强局部感知能力。具体地,我们提出了一个关联块注意力模块来引入图像块之间的局部关联关系。此外,我们还设计了一个细节挖掘模块,从而可以利用局部特征来引导模型学习着去关注那些弱响应区域。最后,我们在两大公开数据集CUB-200-2011和ILSVRC上进行了充分的实验来验证我们方法的有效性。


05
基于特征生成和假设验证的可靠人脸活体检测
Feature Generation and Hypothesis Verification for Reliable Face Anti-Spoofing
人脸识别技术已广泛应用于各种智能系统中,与此同时,无穷无尽的“人脸表示攻击”不断地威胁着智能系统的安全。为了赋予智能系统足够的防御能力,人脸活体检测(face anti-spoofing)技术应运而生。尽管当前的活体检测方法在已知域中表现优异,但对于未知域中的攻击则不能良好的防御。针对该泛化问题,有两大类方法被广泛研究:领域通用(domain generalization)和特征解耦(representation disentanglement)。然而,它们都有各自的局限性:(1)考虑到未知域中的样本,很难将所有人脸映射到一个共享的、足够泛化的特征空间。如果未知域中的人脸没有被映射到该特征空间中的已知区域,模型将会产生不准确的预测。(2)考虑到未知种类的攻击,很难将所有攻击痕迹(spoof trace)精确解耦。因此在本文中,我们提出了一种特征生成和假设验证的算法框架。首先,我们引入了特征生成网络,用于生成真人和已知攻击的假设(hypotheses)。随后,设计了两个假设验证模块,用于判断输入人脸在多大程度上来自真人特征空间和真人特征分布。并且,我们分析了该算法框架与贝叶斯不确定性估计(Bayesian Uncertainty Estimation)的关联,为该算法框架的有效性提供了理论支持。实验结果表明,我们的框架在跨场景和跨攻击类型两种不同的配置下,均获得了SOTA的效果。

06
基于渐进式增强学习的人脸伪造图像检测
Exploiting Fine-grained Face Forgery Clues via Progressive Enhancement Learning
随着人脸编辑技术的快速发展,人脸内容取证引起了广泛的关注。在针对伪造人脸图像的检测上,大多数现有方法往往尝试利用频域信息来挖掘伪造痕迹,然而这些方法对频域信息的利用较为粗糙,且传统的网络结构难以应用于频率下的细微信息的提取。
为了解决上述问题,本文提出了一种渐进式的增强学习框架来同时利用RGB信息和细粒度的频率信息。首先,本文基于滑动窗口和离散余弦变换将输入RGB图像转换成细粒度的频率分量,来充分在频域空间对真假痕迹解耦。随后,本文基于双流网络引入了自增强模块和互增强模块,其中自增强模块可以捕捉不同输入空间下的篡改痕迹,而互增强模块可以互补加强双流的特征交互。通过这种渐进式的特征增强流程,能够有效利用细粒度的频率信息以及RGB信息来定位细微的伪造痕迹。
大量的实验表明我们所提出的方法在FaceForensics++、WildDeepfake等多个数据集同源设置下效果优于现有的方法,同时详细的可视化也充分证明了我们方法的鲁棒性和可解释性。

07
基于双重对比学习的人脸伪造图像检测
Dual Contrastive Learning for General Face Forgery Detection
由于人脸伪造技术不断迭代更新,如何保持检测模型在未知攻击上的泛化性成为了目前人脸伪造检测领域的一大挑战。先前工作往往都采用基于交叉熵损失的分类框架来建模人脸伪造检测问题,然而这种范式过于强调类别层面的差异,但忽略了每个样本特有的伪造信息,限制了模型在未知领域的通用性。
为了解决上述问题,本文提出了一种新型的人脸伪造检测框架,即双重对比学习(Dual Contrastive Learning,DCL),其针对性地构造了不同种类的样本对,并在不同粒度上进行对比学习得到更泛化的特征表示。具体而言,本文结合困难样本选择策略提出了实例间对比学习(Inter-ICL),促进任务相关的判别性特征学习。此外,为了进一步探索本质上的差异引入了实例内对比学习(Intra-ICL),来进一步捕捉伪造人脸中普遍存在的特征不一致性。
本文构造了泛化性评估实验,即在FaceForensics++等数据集上训练,并在DFD和DFDC等其他包含未知攻击的学术数据集下评估模型效果。大量实验和分析表明我们方法能显著提升模型的泛化性。

08
基于动态不一致性学习的人脸伪造视频检测
Delving into the local: Dynamic Inconsistency Learning for DeepFake Video Detection
在人脸伪造视频的检测上,现有的Deepfake视频检测方法试图基于时序建模来捕获真假人脸之间的判别特征,然而这些方法往往对稀疏采样的视频帧进行建模,忽略了相邻帧之间的局部运动信息。由于局部运动信息中包含了帧间的运动不一致性,因此可以作为 DeepFake 视频检测的重要线索。
为了解决这一问题,本文深入研究了视频中的局部运动信息,并提出了一种新视频采样单元“Snippet”,该单元包含一些局部连续视频帧。此外,本文精心设计了Intra-Snippet Inconsistency Module(Intra-SIM)和 Inter-Snippet Interaction Module(InterSIM)来建立不一致性动态建模框架。具体来说,Intra-SIM 应用双向时间差分运算和可学习的卷积核来挖掘每个“Snippet”内的细微运动。然后 Inter-SIM 用以促进跨 “Snippet” 间的信息交互来形成全局表示。 此外,IntraSIM 和 Inter-SIM 采用交替方式进行工作,可以方便插入现有的 2D 基础网络结构。
我们方法在FaceForensics++、Celeb-DF等多个学术数据集上视频评估标准下达到SOTA,丰富的可视化分析进一步证明了我们方法的有效性。

09
基于双流更新的视觉Transformer动态加速方法
Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
视觉Transformer 通过自注意力机制捕获短程和长程视觉依赖的能力使其在各种计算机视觉任务中显示出巨大的潜力,但是长程感受野同样带来了巨大的计算开销,特别是对于高分辨率视觉任务。为了能够在保持原有模型准确率的前提下,降低模型计算复杂度,从而使得视觉 Transformer成为一种更加通用、高效、低廉的解决框架,我们提出了Evo-ViT,基于双流token更新的视觉transformer动态加速方法。该方法在保持了完整空间结构的同时给高信息量token和低信息量token分配不同的计算通道。从而在不改变网络结构的情况下,以极低的精度损失大幅提升直筒状和金字塔压缩型的Transformer模型推理性能。其中,我们提出的基于全局class attention的token选择策略通过增强层间的通信联系实现稳定token选择,相比以往方法,无需依靠外部的可学习网络来对每一层的token进行选择,也无需基于训练好的网络进行token裁剪。在ImageNet 1K数据集下,Evo-ViT可以提升DeiT-S 60%推理速度的同时仅仅损失0.4%的精度。

10
基于伪任务知识保存的行人重识别持续学习方法
Lifelong Person Re-identification by Pseudo Task Knowledge Preservation
现实应用中的行人重识别数据来源在时空上通常是分散的,这要求模型在不忘记旧知识的前提下,能够持续学习到新知识。数据的时空分散会带来任务相关的域差异,从而导致持续学习中的灾难性遗忘。 为了解决这个问题,我们设计了一个伪任务知识存留框架来充分挖掘任务间的信息用于知识保存。该框架由一个能将当前任务特征映射到旧任务特征空间的伪任务变换模块,一个任务相关的域一致性学习模块,一个基于伪任务的知识蒸馏模块和身份判别模块组成。我们的方法在LReID任务上显著地超过了之前SOTA,并获得了可以媲美联合训练的效果。


11
通过Overlap估计引导局部特征点的匹配
Guide Local Feature Matching by Overlap Estimation
尺度不变情况下的特征匹配问题从传统的SIFT到最近基于CNN的方法都没有得到很好解决。常规的局部特征点匹配方法直接从全图考虑,进行特征点提取匹配。本文提出的OETR方法,在借助CNN和Transformer强大特征交互能力,直接估计出两张图片之间的Overlap区域。通过将特征点的提取匹配限制在两张图片的Overlap区域内,并对Overlap区域进行缩放,有效降低两张图片尺度差异大时特征匹配的难度,在多个Benchmark上的实验获得SOTA的性能。此外,OETR可以作为一个前处理模块,应用于任意的局部特征提取匹配方法,帮助现有的特征匹配提升效果。

12
基于笔画-语义上下文感知的场景文本识别对比学习方法
Perceiving Stroke-Semantic Context: Hierarchical Contrastive Learning for Robust Scene Text Recognition
本文提出了一种针对场景文本识别(Scene Text Recognition, STR)任务的自监督表示学习新方法——感知笔画-语义上下文(Perceiving Stroke-Semantic Context, PerSec)。针对场景文本图像兼具视觉性和语义性的特点,本方法提出了双重上下文感知器,可以对无标签的文本图像数据同时从低级别笔画和高级别语义上下文空间中进行对比学习。在场景文本识别的标准数据集上的实验结果表明,本文提出的框架可以为基于ctc和基于注意力的解码器生成更为鲁棒的特征表示。为了充分挖掘该方法的潜力,我们还收集了1亿张无标签文本图像作为数据集UTI-100M,涵盖5个场景和4种语言。通过利用上亿级的无标签数据进行预训练,得到的编码器特征对于下游文本识别的性能优良进一步提升。此外,PerSec学习的特征表示还展现除了很强的泛化能力,特别是在仅有少量有标签数据的场景下。


13
基于动作引导序列生成的语法错误纠正方法
Sequence-to-Action: Grammatical Error Correction with Action Guided Sequence Generation
本文针对语法错误纠正(Grammatical Error Correction, GEC)任务的特点,将seq2seq以及序列标注两种经典模型的优点结合起来,提出了一个全新的序列-动作(Sequence-to-Action, S2A)模型。S2A模块将源语句和目标语句同时作为输入,并且能够在预测每个token之前自动生成token级别的操作序列(包括“跳过”、“拷贝”和“生成”三种操作)。之后,这些动作与基本的seq2seq框架融合进行最终的结果预测。在中英文GEC任务的基准数据集上的实验结果表明,本文提出的模型性能远优于业内其他方法,同时能够显著缓解过度校正问题。此外,与序列标记模型相比,本文方法在生成结果上能够保持更好的通用性和多样性。

特别提醒:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕。
