本篇文章给大家带来了关于Oracle的相关知识,其中主要介绍了内存分配和调优的相关问题,oracle 的内存可以按照共享和私有的角度分为系统全局区和进程全局区,也就是SGA和PGA,下面就一起来看一下,希望对大家有帮助。

推荐教程:《Oracle学习教程》
一、概述
oracle 的内存可以按照共享和私有的角度分为系统全局区和进程全局区,也就是 SGA和 PGA(process global area or private global area)。对于 SGA 区域内的内存来说,是共享的全局的,在 UNIX 上,必须为 oracle 设置共享内存段(可以是一个或者多个),因为 oracle 在UNIX 上是多进程;而在 WINDOWS 上 oracle 是单进程(多个线程),所以不用设置共享内存段。PGA 是属于进程(线程)私有的区域。在 oracle 使用共享服务器模式下(MTS),PGA中的一部分,也就是 UGA 会被放入共享内存 large_pool_size 中。
发张图oracle内存架构组成,按照图上面的显示可以一目了然关键的参数和参数名称:
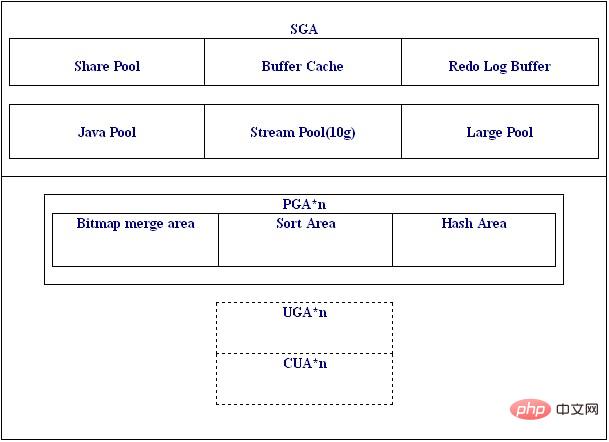
对于 SGA 部分,我们通过 sqlplus 中查询可以看到:
SQL> select * from v$sga; NAME VALUE ---------- -------------------- Fixed Size 454032 Variable Size 109051904 Database Buffers 385875968 Redo Buffers 667648
Fixed Size:
oracle 的不同平台和不同版本下可能不一样,但对于确定环境是一个固定的值,里面存储了 SGA 各部分组件的信息,可以看作引导建立 SGA 的区域。
Variable Size :
包含了 shared_pool_size、java_pool_size、large_pool_size 等内存设置
Database Buffers :
指数 据缓 冲区:
在 8i 中包 含 db_block_buffer*db_block_size、buffer_pool_keep、buffer_pool_recycle 三 部 分内 存 。
在 9i 中 包 含 db_cache_size 、db_keep_cache_size、db_recycle_cache_size、db_nk_cache_size。
Redo Buffers :
指日志缓冲区,log_buffer。在这里要额外说明一点的是,对于 v$parameter、v$sgastat、v$sga 查询值可能不一样。v$parameter 里面的值,是指用户在初
始化参数文件里面设置的值,v$sgastat 是 oracle 实际分配的日志缓冲区大小(因为缓冲区的分配值实际上是离散的,也不是以 block 为最小单位进行分配的),
v$sga 里面查询的值,是在 oracle 分配了日志缓冲区后,为了保护日志缓冲区,设置了一些保护页,通常我们会发现保护页大小大约是 11k(不同环境可能不一样)。
二、SGA内参数及设置:
2.1 Log_buffer
对于日志缓冲区的大小设置,通常我觉得没有过多的建议,因为参考 LGWR 写的触发条件之后,我们会发现通常超过 3M 意义不是很大。作为一个正式系统,
可能考虑先设置这部分为 log_buffer=3—5M 大小,然后针对具体情况再调整。
log_buffer是Redo log的buffer。
因此在这里必须要了解Redo Log的触发事件(LGWR)
1、当redo log buffer的容量达到1/3
2、设定的写redo log时间间隔到达,一般为3秒钟。
3、redo log buffer中重做日志容量到达1M
4、在DBWn将缓冲区中的数据写入到数据文件之前
5、每一次commit–提交事务。
上面的结论可以换句话说
1、log_buffer中的内容满1/3,缓存刷新一次。
2、最长间隔3秒钟,缓存刷新一次
3、log_buffer中的数据到达1M,缓存刷新一次。
4、每次提交一个“事务”,缓存刷新一次
2.2 Large_pool_size
对于大缓冲池的设置,假如不使用 MTS,建议在 20—30M 足够了。这部分主要用来保存并行查询时候的一些信息,还有就是 RMAN 在备份的时候可能会使用到。
如果设置了MTS,则由于 UGA 部分要移入这里,则需要具体根据 server process 数量和相关会话内存参数的设置来综合考虑这部分大小的设置。
2.3 Java_pool_size
假如数据库没有使用 JAVA,我们通常认为保留 10—20M 大小足够。事实上可以更少,甚至最少只需要 32k,但具体跟安装数据库的时候的组件相关(比如 http server)。
2.4 Shared_pool_size
Shared_pool_size的开销通常应该维持在300M 以内。除非系统使用了大量的存储过程、函数、包,
比如 oracle erp 这样的应用,可能会达到 500M 甚至更高。于是我们假定一个 1G 内存的系统,可能考虑
设置该参数为 100M,2G 的系统考虑设置为 150M,8G 的系统可以考虑设置为 200—300M
2.5SGA_MAX_SIZE
SGA区包括了各种缓冲区和内存池,而大部分都可以通过特定的参数来指定他们的大小。但是,作为一个昂贵的资源,一个系统的物理内存大小是有限。
尽管对于CPU的内存寻址来说,是无需关系实际的物理内存大小的(关于这一点,后面会做详细的介绍),但是过多的使用虚拟内存导致page in/out,
会大大影响系统的性能,甚至可能会导致系统crash。所以需要有一个参数来控制SGA使用虚拟内存的最大大小,这个参数就是SGA_MAX_SIZE。当实例启动后,
各个内存区只分配实例所需要的最小大小,在随后的运行过程中,再根据需要扩展他们的大小,而他们的总和大小受到了SGA_MAX_SIZE的限制。
对于OLTP系统,参考:
|
系统内存 |
SGA_MAX_SIZE值 |
|
1G |
400-500M |
|
2G |
1G |
|
4G |
2500M |
|
8G |
5G |
2.6 PRE_PAGE_SGA
oracle实例启动时,会只载入各个内存区最小的大小。而其他SGA内存只作为虚拟内存分配,
只有当进程touch到相应的页时,才会置换到物理内存中。但我们也许希望实例一启动后,所有SGA
都分配到物理内存。这时就可以通过设置PRE_PAGE_SGA参数来达到目的了。这个参数的默认值
为FALSE,即不将全部SGA置入物理内存中。当设置为TRUE时,实例启动会将全部SGA置入物理
内存中。它可以使实例启动达到它的最大性能状态,但是,启动时间也会更长(因为为了使所有SGA
都置入物理内存中,oracle进程需要touch所有的SGA页)。
2.7 LOCK_SGA
为了保证SGA都被锁定在物理内存中,而不必页入/页出,可以通过参数LOCK_SGA来控制。
这个参数默认值为FALSE,当指定为TRUE时,可以将全部SGA都锁定在物理内存中。当然,
有些系统不支持内存锁定,这个参数也就无效了。
2.8 SGA_TARGET
这里要介绍的时Oracle10g中引入的一个非常重要的参数。在10g之前,SGA的各个内存区
的大小都需要通过各自的参数指定,并且都无法超过参数指定大小的值,尽管他们之和可能并
没有达到SGA的最大限制。此外,一旦分配后,各个区的内存只能给本区使用,相互之间是不能共享的。
拿SGA中两个最重要的内存区Buffer Cache和Shared Pool来说,它们两个对实例的性能影响最大,
但是就有这样的矛盾存在:在内存资源有限的情况下,某些时候数据被cache的需求非常大,
为了提高buffer hit,就需要增加Buffer Cache,但由于SGA有限,只能从其他区“抢”过来——如缩小Shared Pool,
增加Buffer Cache;而有时又有大块的PLSQL代码被解析驻入内存中,导致Shared Pool不足,
甚至出现4031错误,又需要扩大Shared Pool,这时可能又需要人为干预,从Buffer Cache中将内存夺回来。
有了这个新的特性后,SGA中的这种内存矛盾就迎刃而解了。这一特性被称为自动共享内存管理
(Automatic Shared Memory Management ASMM)。而控制这一特性的,也就仅仅是这一个参数SGA_TARGE。
设置这个参数后,你就不需要为每个内存区来指定大小了。SGA_TARGET指定了SGA可以使用的最大内存大小,
而SGA中各个内存的大小由Oracle自行控制,不需要人为指定。Oracle可以随时调节各个区域的大小,使之达到系
统性能最佳状态的个最合理大小,并且控制他们之和在SGA_TARGET指定的值之内。一旦给SGA_TARGET指定值后
(默认为0,即没有启动ASMM),就自动启动了ASMM特性。
三、oracle 内存调优办法
当项目的生产环境出现性能问题,我们如何通过判断那些参数需要调整呢?
3.1 检查ORACLE实例的Library Cache命中率:
标准:一般是大于99% 检查方式:
select 1-(sum(reloads)/sum(pins)) "Library cache Hit Ratio" from v$librarycache;
处理措施: 如果Library cache Hit Ratio的值低于99%,应调高shared_pool_size的大小。通过sqlplus连接数据库执行如下命令,调整shared_pool_size的大小:
SQL>alter system flush shared_pool; SQL>alter system set shared_pool_size=设定值 scope=spfile;
3.2 检查ORACLE实例的Data Buffer(数据缓冲区)命中率:
标准:一般是大于90% 检查方式:
select 1 - (phy.value / (cur.value + con.value)) "HIT RATIO" from v$sysstat cur, v$sysstat con, v$sysstat phy where cur.name = 'db block gets' and con.name = 'consistent gets' and phy.name = 'physical reads';
处理措施:
如果HIT RATIO的值低于90%,应调高db_cache_size的大小。通过sqlplus连接数据库执行如下命令,
调整db_cache_size的大小
SQL>alter system set db_cache_size=设定值 scope=spfile
3.3 检查ORACLE实例的Dictionary Cache命中率:
标准:一般是大于95%
检查方式:
select 1 - (sum(getmisses) / sum(gets)) "Data Dictionary Hit Ratio" from v$rowcache;
处理措施:
如果Data Dictionary Hit Ratio的值低于95%,应调高shared_pool_size的大小。通过sqlplus连接数据库执行如下命令,调整shared_pool_size的大小:
SQL>alter system flush shared_pool; SQL>alter system set shared_pool_size=设定值 scope=spfile;
3.4 检查ORACLE实例的Log Buffer命中率:
标准:一般是小于1%
检查方式:
select (req.value * 5000) / entries.value "Ratio" from v$sysstat req, v$sysstat entries where req.name = 'redo log space requests' and entries.name = 'redo entries';
处理措施:
如果Ratio高于1%,应调高log_buffer的大小。通过sqlplus连接数据库执行如下命令,调整log_buffer的大小:
SQL>alter system set log_buffer=设定值 scope=spfile;
3.5 检查undo_retention:
标准:undo_retention 的值必须大于max(maxquerylen)的值
检查方式:
col undo_retention format a30 select value "undo_retention" from v$parameter where name='undo_retention'; select max(maxquerylen) From v$undostat Where begin_time>sysdate-(1/4);
处理措施:
如果不满足要求,需要调高undo_retention 的值。通过sqlplus 连接数据库执行如下命令,调整undo_retention 的大小:
SQL>alter system set undo_retention= 设定值 scope=spfile;
注:
32bit 和 64bit 的问题
对于 oracle 来说,存在着 32bit 与 64bit 的问题。这个问题影响到的主要是 SGA 的大小。在 32bit 的数据库下,通常 oracle 只能使用不超过 1.7G 的内存,即使我们拥有 12G 的内存,但是我们却只能使用 1.7G,这是一个莫大的遗憾。假如我们安装 64bit 的数据库,我们就可以使用很大的内存,我们几乎不可能达到上限。但是 64bit 的数据库必须安装在 64bit 的操作系统上,可惜目前 windows 上只能安装 32bit 的数据库,我们通过下面的方式可以查看数据库是 32bit 还是 64bit
但是在特定的操作系统下,可能提供了一定的手段,使得我们可以使用超过 1.7G 的内存,达到 2G 以上甚至
