怎么使用Python下载大量图像?下面本篇文章给大家介绍一下使用Python进行多线程并发下载图片的方法,希望对大家有所帮助!

程序员必备接口测试调试工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api设计、调试、文档、自动化测试工具
后端、前端、测试,同时在线协作,内容实时同步
有时候,下载大量图像需要几个小时——让我们来解决这个问题
我明白了——你已经厌倦了等待你的程序下载图像。有时我必须下载数千张图像需要几个小时,而且你不可能一直等待你的程序完成下载这些愚蠢的图像。你有很多重要的事情要做。
让我们构建一个简单的图像下载器脚本,它将读取一个文本文件并以超快的速度下载一个文件夹中列出的所有图像。
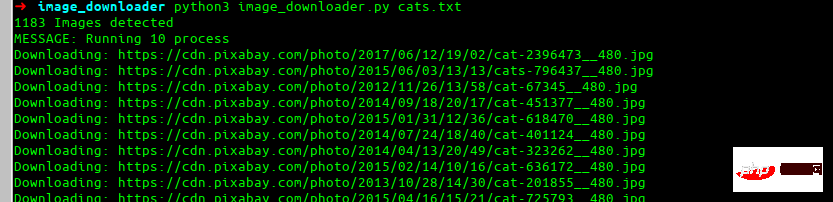
最终效果
这就是我们最终要构建的效果。

安装依赖项
让我们安装每个人最喜欢的 requests 库。
pip install requests
现在,我们将看到一些用于下载单个 URL 并尝试自动查找图像名称以及如何使用重试的基本代码。
import requests res = requests.get(img_url, stream=True) count = 1 while res.status_code != 200 and count <= 5: res = requests.get(img_url, stream=True) print(f'Retry: {count} {img_url}') count += 1
在这里,我们重试下载图像五次,以防失败。现在,让我们尝试自动找到图像的名称并保存它。
import more required library import io from PIL import Image # lets try to find the image name image_name = str(img_url[(img_url.rfind('/')) + 1:]) if '?' in image_name: image_name = image_name[:image_name.find('?')]
解释
假设我们要下载的 URL 是:
instagram.fktm7-1.fna.fbcdn.net/vp…
好吧,这是一团糟。让我们分解一下代码对 URL 的作用。我们首先使用 rfind 找到最后一个正斜杠(/),然后选择之后的所有内容。这是结果:
65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111
现在我们的第二部分找到一个 ?,然后只取它前面的任何东西。
这是我们最终的图像名称:
65872070_1200425330158967_6201268309743367902_n.jpg
这个结果非常好,适用于大多数用例。
现在我们已经下载了图像名称和图像,我们将保存它。
i = Image.open(io.BytesIO(res.content)) i.save(image_name)
如果你在想,「我到底应该怎么使用上面的代码?」那么你的想法是正确的。这是一个漂亮的函数,我们在上面所做的一切都被扁平处理了。在这里,我们还测试了下载的类型是否为图像,以防找不到图像名称。
def image_downloader(img_url: str): """ Input: param: img_url str (Image url) Tries to download the image url and use name provided in headers. Else it randomly picks a name """ print(f'Downloading: {img_url}') res = requests.get(img_url, stream=True) count = 1 while res.status_code != 200 and count <= 5: res = requests.get(img_url, stream=True) print(f'Retry: {count} {img_url}') count += 1 # checking the type for image if 'image' not in res.headers.get("content-type", ''): print('ERROR: URL doesnot appear to be an image') return False # Trying to red image name from response headers try: image_name = str(img_url[(img_url.rfind('/')) + 1:]) if '?' in image_name: image_name = image_name[:image_name.find('?')] except: image_name = str(random.randint(11111, 99999))+'.jpg' i = Image.open(io.BytesIO(res.content)) download_location = 'cats' i.save(download_location + '/'+image_name) return f'Download complete: {img_url}'
现在,你可能会问:「这个人所说的多处理在哪里?」。
这很简单。我们将简单地定义我们的池并将我们的函数和图像 URL 传递给它。
results = ThreadPool(process).imap_unordered(image_downloader, images_url) for r in results: print(r)
让我们把它放在一个函数中:
def run_downloader(process:int, images_url:list): """ Inputs: process: (int) number of process to run images_url:(list) list of images url """ print(f'MESSAGE: Running {process} process') results = ThreadPool(process).imap_unordered(image_downloader, images_url) for r in results: print(r)
再一次,你可能会说,「这一切都很好,但我想立即开始下载我的 1000 张图像列表。我不想复制和粘贴所有这些代码并试图弄清楚如何合并所有内容。」
这是一个完整的脚本。它执行以下操作:
-
以图像列表文本文件和进程号作为输入
-
按照您想要的速度下载它们
-
打印下载文件的总时间
-
还有一些不错的函数可以帮助我们读取文件名并处理错误和其他东西
完整的脚本
# -*- coding: utf-8 -*- import io import random import shutil import sys from multiprocessing.pool import ThreadPool import pathlib import requests from PIL import Image import time start = time.time() def get_download_location(): try: url_input = sys.argv[1] except IndexError: print('ERROR: Please provide the txt filen$python image_downloader.py cats.txt') name = url_input.split('.')[0] pathlib.Path(name).mkdir(parents=True, exist_ok=True) return name def get_urls(): """ 通过读取终端中作为参数提供的 txt 文件返回 url 列表 """ try: url_input = sys.argv[1] except IndexError: print('ERROR: Please provide the txt filen Example nn$python image_downloader.py dogs.txt nn') sys.exit() with open(url_input, 'r') as f: images_url = f.read().splitlines() print('{} Images detected'.format(len(images_url))) return images_url def image_downloader(img_url: str): """ 输入选项: 参数: img_url str (Image url) 尝试下载图像 url 并使用标题中提供的名称。否则它会随机选择一个名字 """ print(f'Downloading: {img_url}') res = requests.get(img_url, stream=True) count = 1 while res.status_code != 200 and count <= 5: res = requests.get(img_url, stream=True) print(f'Retry: {count} {img_url}') count += 1 # checking the type for image if 'image' not in res.headers.get("content-type", ''): print('ERROR: URL doesnot appear to be an image') return False # Trying to red image name from response headers try: image_name = str(img_url[(img_url.rfind('/')) + 1:]) if '?' in image_name: image_name = image_name[:image_name.find('?')] except: image_name = str(random.randint(11111, 99999))+'.jpg' i = Image.open(io.BytesIO(res.content)) download_location = get_download_location() i.save(download_location + '/'+image_name) return f'Download complete: {img_url}' def run_downloader(process:int, images_url:list): """ 输入项: process: (int) number of process to run images_url:(list) list of images url """ print(f'MESSAGE: Running {process} process') results = ThreadPool(process).imap_unordered(image_downloader, images_url) for r in results: print(r) try: num_process = int(sys.argv[2]) except: num_process = 10 images_url = get_urls() run_downloader(num_process, images_url) end = time.time() print('Time taken to download {}'.format(len(get_urls()))) print(end - start)
将其保存到 Python 文件中,然后运行它。
python3 image_downloader.py cats.txt
这是 GitHub 存储库的链接。
用法
python3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process>
这将读取文本文件中的所有 URL,并将它们下载到名称与文件名相同的文件夹中。
num_of_process 是可选的(默认情况下,它使用 10 个进程)。
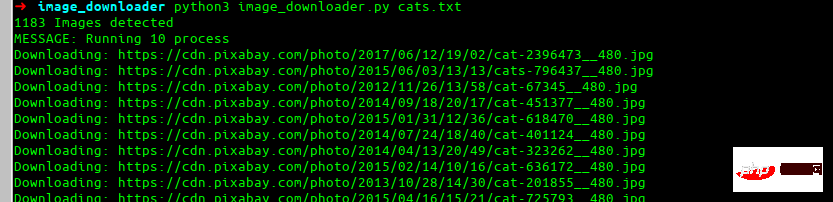
例子
python3 image_downloader.py cats.txt

我很乐意就如何进一步改进这一点做出任何回应。
【
